The set 
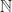
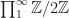
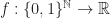
One question one can ask is why historically we started with 
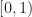

I do not have complete answers to these questions, perhaps Zygmund’s beautiful book on trigonometric series had a nontrivial influence on historical development of Fourier analysis on 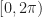
In this post I will try briefly talk about Fourier analysis on
Harmonic analysis on
One usually considers Haar measure 
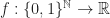

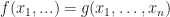
Orthonormal system on 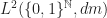
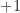
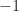

I have seen 4 different enumerations of this family of functions used in the literature (perhaps there are more). The first 3 of them (original Walsh, Paley, and Walsh–Kaczmarz) is well described in the book F. Schipp, WR. Wade, P. Simon, “Walsh series: an introduction to dyadic harmonic analysis”, see Section 1.4. The 4th one which I find kind of exceptional is not there.
1). Walsh’s original enumeration: Walsh defined his system recursively. Later, it turned out that they can be written as follows: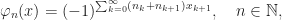
where 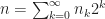


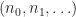

Partial sums 
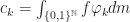


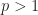
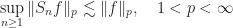
Moreover 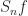
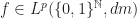

Luzin asked in the trigonometric case on the unit circle 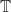

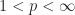
Fejer means are bounded, i.e.,
In the book F. Schipp, WR. Wade, P. Simon, there is a more “martingale proofs” of these results. Dyadic martingales naturally appear here. For example, 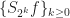
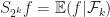
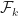
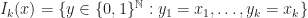

is exactly Doob’s maximal inequality. The book F. Schipp, WR. Wade, P. Simon, “Walsh series: an introduction to dyadic harmonic analysis” provides more martingale techniques. The paper A guide to Calreson’s theorem by Ciprian Demeter has more time-frequency analysis introduction.
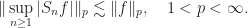


- Paley’s enumeration (Walsh–Paley functions). In 1932, Paley proposed a different enumeration of Walsh functions
Paley’s enumeration perhaps is more close to the classical trigonometric systemand
. We can “identify”
for some. This identification is not unique, for example,
can be written as
and also as
. Among these two one choose the first one, i.e., when number of 1’s terminate starting from some place. Such bad points are not too many, they have zero measure so we do not bother with them. In particular
is defined for
. Then
In general,
Frequenciesare independent pretty much in the same way as
are independent: Khinchin’s inequality holds for both of them
, and
.
One has the notion of “dyadic derivative”
provided that the sum converges. Perhaps one should call it “dyadic Laplacian” instead of the derivative. One can verify that Walsh–Paley functions are eigenfunctions:. One can study polynomials of degree
, say finite sums
, and ask questions similar to Markov–Brother’s and Bernstein estimates for such polynomials. One can ask regularity questions: if
how regular it is on
- Sneider’s enumeration (Walsh-Kaczmarz system) was introduced by Sneider:
I won’t say much about this system except that the samewhere
is either Walsh, Walsh–Paley, Walsh–Kaczmarz, for
are the same. In fact
.


![\begin{aligned} w_{2^{k}}(s) = (-1)^{s_{k+1}} =\mathrm{sign}(\sin(2^{k+1} \pi s)) \approx \sin(2^{k+1} \pi s), \quad s \in (0,1]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+w_%7B2%5E%7Bk%7D%7D%28s%29+%3D+%28-1%29%5E%7Bs_%7Bk%2B1%7D%7D+%3D%5Cmathrm%7Bsign%7D%28%5Csin%282%5E%7Bk%2B1%7D+%5Cpi+s%29%29+%5Capprox+%5Csin%282%5E%7Bk%2B1%7D+%5Cpi+s%29%2C+%5Cquad+s+%5Cin+%280%2C1%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
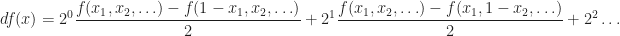
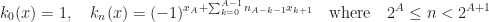
Frequencies: when working with these 3 enumerations one usually thinks that 

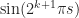
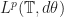

- Probabilistic enumeration (from independent towards dependent). In this enumeration the concept of “high/low frequencies” is changed in a very opposite way. In fact, the elements
will be the lowest frequencies, say frequencies of degree
. Elements
where
. These are precisely Walsh functions
,
. In a certain sense enumeration starts from “independent frequencies to dependent ones“, and probabilistic ideas, measure concentration phenomena, dimension independent phenomena, and the concept of “independence” happen to be useful. The goal is to represent functions
Of course, if one takes, writes into Walsh–Paley system
, and wants to rearrange the terms to write in the form (1) then rearranged infinity sums may give different results unless
which is very unlikely for a “typical”
. However, if one considers functions
Thus if we consider functions
The latter notation seems to be compact and convenient. Hereare Fourier coefficients, and
are Walsh functions (enumerated in a strange way) indexed by the sets
. Since this enumeration works well provided that
wheredenotes the cardinality of the set
with uniform bound for all,
, for all
, and all
Interesting connection arises with Gauss space. For example
whereis degree
probabilists’ Hermite polynomial,
is the standard normal Gaussian random variable, and the convergence is in the sense of distributions. By Taking tensor products of the above example one recovers Hermite polynomials on
with arbitrary
. So, because of this limit, it is reasonable to think about
Dscrete Laplacian is defined in a different way
where. One also considers discrete gradient
One has integration by parts formula
for all functionsdepending on the first
satisfies heat equation. Discrete gradient
when applied tofor some smooth bounded
, converges to the classical derivative
for any smooth functions. The case
is a typical application. Denoting
, then
and the latter expression can be extended in a natural way for allas a multilinear classical polynomial in
tools from approximation theory enter in an unexpected way applied to actual degree
have an extra property
and this gives more cancelations when proving statements for all real valued functions.
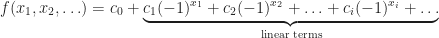
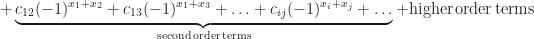
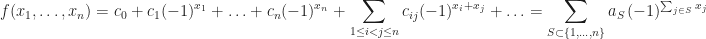
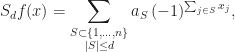


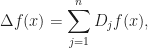


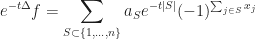

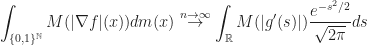

To summarize: Harmonic analysis on
